
© Copyright 2006-2008 Грибов Игорь, e-mail: gribov@depni.sinp.msu.ru
Изменения в версиях. Базы данных для встроенных приложний. Программная реализация неупорядоченного списка. Упорядоченный массив с первичным ключем. Упорядоченный массив с внешними ключами.
Полная версия раздела задается в виде: версия.подверсия.выпуск.
Номер версии увеличивается при появлении глав, затрагивающих не рассмотренные ранее вопросы. Названия этих глав выносятся в оглавление раздела. Подверсия увеличивается, когда в существующие главы добавляются новые абзацы, рисунки, либо значительно перерабатывается имеющийся материал, существенно изменяя содержание главы. А при внесении лишь незначительных правок в существующие главы увеличивается номер выпуска.
Для хранения и доступа к информации языки программирования высокого уровня предоставляют некоторый базовый набор абстрактных структур данных. Как правило они включают в себя переменные различных типов, массивы, записи и т.п. Доступ к таким структурам осуществляется по имени либо набору имен, которые в конечном счете определяют адрес размещения данных. В практических приложениях нередко возникает необходимость организации доступа к регулярным (состоящим из множества одинаковых записей) структурам данных по значению тех или иных полей этих структур. С этой целью регулярные структуры организуются в базы данных. В настоящей главе приводится их возможная реализация, ориентированная на встроенные приложения. Такая сфера применения обуславливает использование наиболее простых классов баз данных, компактных по коду и оптимизированных прежде всего для поиска необходимых записей. В нашем рассмотрении все базы используют в качестве хранилища данных массивы фиксированного либо переменного размера и размещаются только в оперативной памяти микроконтроллера либо универсальной ЭВМ.
Доступ к записям базы данных осуществляется с использованием ключа. Ключ представляет собой набор отдельных полей записи, по значению которых и производится все операции: поиск записи, ее добавление, удаление и другие. База данных может иметь несколько ключей, позволяя осуществлять доступ по различным логическим путям. Некоторые базы поддерживают возможность применения дублированных ключей, когда несколько записей имеют одинаковые значения всех ключевых полей. Однако работать с такими данными весьма неудобно и следует настоятельно рекомендовать использование лишь уникальных ключей. Если существующих полей недостаточно для того, чтобы сформировать такой ключ, целесообразно добавить поле, которое обеспечит уникальность ключа.
В качестве базовых операций с данными будем рассматривать поиск записи по ключу, добавление новой записи, ее удаление и переход к последующей или предшествующей в ключевом порядке записи. Для характеристики времени выполнения базовых операций используется параметр O (О большое), который характеризует относительный порядок необходимого числа элементарных машинных операций в зависимости от числа записей базы (ее размера). Так, O(N) означает, что время выполнения базовой операции пропорционально размеру базы, а O(logN) указывает на то, что время операции увеличивается лишь пропорционально логарифму от числа записей базы.
В неупорядоченном списке данные размещаются по мере поступления без какой-либо сортировки. В случае удаления записи на ее место может быть помещена новая запись с произвольным значением ключа.
Временные характеристики и алгоритмы операций неупорядоченного списка:
|
Базовая операция |
Поиск |
Добавление |
Удаление |
Переход |
|---|---|---|---|---|
|
Относительный порядок времени выполнения |
O(N) |
O(N) |
O(N) |
O(N) |
|
Алгоритм выполнения базовой операции |
Сканирование базы. |
Сканирование базы. |
Сканирование базы. |
Сканирование базы. |
Таким образом, все основные операции с данными, размещенными в неупорядоченном списке, достаточно тяжелы – число необходимых элементарных операций растет пропорционально размеру базы. Тем не менее, простота программной реализации такого списка вполне оправдывает его использование, когда число записей базы не превышает порядка ста. Отметим, что работа с неупорядоченным списком алгоритмически подобна использованию условных операторов if, else if для выборочного доступа к обычным данным.
Не столь редко встречаются ситуации, когда диапазон значений ключа ограничен настолько, что становится возможным резервирование записей для всех возможных его значений. Это позволяет сформировать максимально эффективную базу данных с прямой адресацией каждой записи, которая хранится в элементе массива, соответствующем значению ключа.

Временные характеристики и алгоритмы операций упорядоченного массива с ограниченным диапазоном значений:
|
Базовая операция |
Поиск |
Добавление |
Удаление |
Переход |
|---|---|---|---|---|
|
Относительный порядок времени выполнения |
O(1) |
O(1) |
O(1) |
O(1) |
|
Алгоритм выполнения базовой операции |
Прямой доступ. |
Прямой доступ. |
Прямой доступ. |
Прямой доступ. |
Итак, время выполнения основных операций не зависит от размера базы. Это делает алгоритм чрезвычайно привлекательным, когда можно выделить достаточно памяти для размещения массива, размер которого равен разности максимального и минимального значений ключа. Отметим в качестве исторического замечания, что в некоторых компиляторах операторы переключателя (switch, case) реализовывались именно как упорядоченный массив с ограниченным числом значений, причем без какой-либо оптимизации. Каждый элемент этого массива содержал адрес перехода на соответствующую ветвь программы. Поэтому задание существенно различных константных выражений переключателя (напримр: case 7..., case 7777777) приводило к чрезмерным затратам оперативной памяти, а нередко и ее полному исчерпанию.
Упорядоченный массив является одним из вариантов классической базы данных и не накладывает ограничений ни на диапазон значений ключа, ни на число различных ключей. Возможны две реализации базы данных в таком массиве с точки зрения организации ключевых полей. Первый способ предполагает упорядочение всей базы по первичному ключу, в качестве которого используется одно или несколько полей данных.
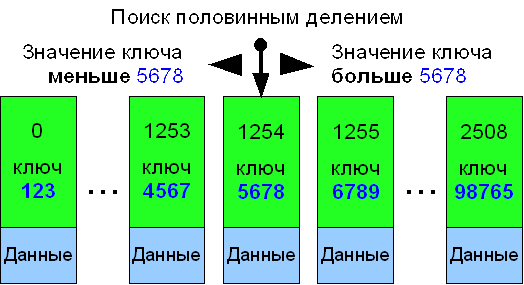
Другая реализация предусматривает разделение базы данных на не упорядоченное тело и один или несколько упорядоченных ключевых массивов. Такой подход дает возможность сформировать несколько различных ключей. Кроме того, снижаются затраты на добавление записей, если размер не ключевых данных достаточно велик. Недостатком такого решения является необходимость дополнения каждой ключевой записи указателем и дублирование ключевых полей в массиве данных. Если такого дублирования не осуществлять, то для полной сборки записи базы потребуется введение обратных указателей от данных на соответствующие им записи ключей.
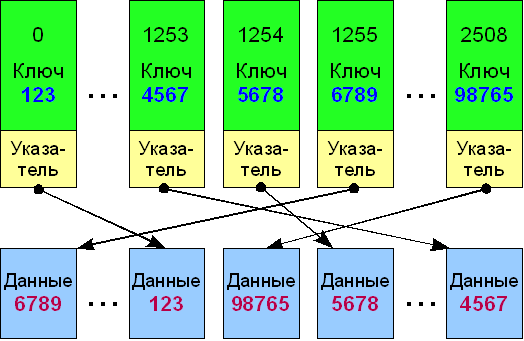
Временные характеристики и алгоритмы операций упорядоченного массива данных:
|
Базовая операция |
Поиск |
Добавление |
Удаление |
Переход |
|---|---|---|---|---|
|
Относительный порядок времени выполнения |
O(logN) гарантированно |
O(N) |
O(N) |
O(1) |
|
Алгоритм выполнения базовой операции |
Половинное деление. |
Поиск, затем раздвижка записей массива. |
Поиск, затем смыкание записей массива. |
Прямая выборка записи. |
Поиск необходимой записи в базе осуществляется методом половинного деления массива ключа, либо самой базы, если она содержит первичный ключ (алгоритм бинарного поиска). Обратите внимание, что время нахождения любой записи базы имеет гарантированно логарифмическую зависимость от ее размера O(logN). Это позволяет прогнозировать максимальное время доступа к записям, что является заметным преимуществом для встроенных приложений. Не случайно алгоритм бинарного поиска включен во многие стандартные библиотеки языков программирования.
Однако, операции добавления и удаления записей сопряжены с необходимость раздвижки или смыкания массива, а потому достаточно тяжелы. Практическое ограничение на размер базы, выполненной в виде упорядоченного массива, составляет порядка десяти тысяч записей, что достаточно для большинства встроенных приложений. В тех случаях, когда определяющим становится снижение затрат именно на операции добавления/удаления, целесообразно рассмотреть возможность использования решений на основе хэш-таблиц, структур данных типа деревьев или специализированных списков.
В программе приведена универсальная реализация трех базовых операций: поиска, добавления и удаления записей. Поскольку неупорядоченный список является минималистским способом организации базы данных, для его хранения целесообразно использовать массив фиксированной длины. Кроме того, сами алгоритмы нередко реализуются специализированным образом. Так, в качестве флага свободного элемента массива нередко используется выделенное значение ключа, а контроль его дублирования может и не осуществляться.
#define NOF_OBJECTS 21 // Максимальный размер базы #define ERROR_NOTFOUND -12 // Запись не найдена #define ERROR_DUPLICATED -11 // Дублированный ключ #define ERROR_MALLOC -10 // Переполнение базы #define ERROR -1 #define OK 1 #define FREE 0 #define BUSY 1 typedef signed char int8; typedef unsigned char unsigned8; typedef signed short int16; typedef unsigned short unsigned16; typedef signed int int32; typedef unsigned int unsigned32;
Некоторые компиляторы интерпретируют типы, не содержащие ключевого слова signed как беззнаковые. Это вызывает смешанные чувства, но поскольку факт имеет место, целесообразно применять явное определение знаковости (signed или unsigned).
typedef struct {
unsigned8 flag; // Флаг занятости элемента массива (активной записи)
unsigned16 key; // Поле ключа
int32 data; // Поле данных
} object; // Структура записи базы
object dbobj[NOF_OBJECTS]; // База данных размещается в массиве фиксированной длины
int16 search_object(object *obj) // so_0
{
int16 cnt;
for (cnt = 0; cnt < NOF_OBJECTS; cnt++) { // so_4
if (dbobj[cnt].flag == BUSY) { // so_5
if (dbobj[cnt].key == obj->key) return cnt; // so_6
}
}
return -1; // so_9
}Функция search_object(obj) осуществляет поиск записи базы по значению ключа. Алгоритм поиска – полное сканирование базы [so_4]. Для каждой активной (занятой) записи [so_5] сравнивается ее ключ [so_6], при совпадении которого функция позвращает не отрицательное число, определяющее элемент массива искомой записи. При неудачном завершении поиска возвращается минус 1 [so_9].
int16 add_object(object *obj) // ao_0
{
int16 cnt, adp;
adp = -1;
for (cnt = 0; cnt < NOF_OBJECTS; cnt++) { // ao_5
if (dbobj[cnt].flag == FREE) { // ao_6
if (adp < 0) adp = cnt; // ao_7
} else {
if (dbobj[cnt].key == obj->key) return ERROR_DUPLICATED; // ao_9
}
}
if (adp < 0) return ERROR_MALLOC; // ao_12
dbobj[adp] = *obj; // ao_13
dbobj[adp].flag = BUSY; // ao_14
return OK;
}Функция add_object(obj) добавляет запись в базу данных. Контроль уникальности ключа вынуждает производить полное сканирование базы [ao_5]. При обнаружении в одной из активных записей совпадающего значения ключа возвращается ошибка дублирования [ao_9]. Для занесения в базу новой записи фиксируется первое обнаруженное свободное место [ao_6, ao_7]. В случае, если такового в базе не оказалось, возвращается ошибка переполнения [ao_12]. В противном случае на обнаруженном свободном месте размещается новая запись [ao_13, ao_14].
int16 delete_object(object *obj) // do_0
{
int16 cnt;
for (cnt = 0; cnt < NOF_OBJECTS; cnt++) {
if (dbobj[cnt].flag == BUSY) { // do_5
if (dbobj[cnt].key == obj->key) { // do_6
dbobj[cnt].flag = FREE; // do_7
return OK;
}
}
}
return ERROR_NOTFOUND; // do_12
}Функция delete_object(obj) помечает соответствующую ключу запись базы [do_6] как свободную [do_7]. В случае, когда необходимая запись среди активных [do_5] не обнаружена, возвращается код ошибки “запись не найдена” [do_12] .
void init_database(void) // id_0
{
int16 cnt;
for (cnt = 0; cnt < NOF_OBJECTS; cnt++) dbobj[cnt].flag = FREE; // id_4
}При инициализации базы все ее записи помечаются как не активные (свободные) [id_4].
В нашей реализации используется дополнение базы данных концевыми записями, которые содержат максимальные и минимальные значения всех ключевых полей и соответственно являются первым и последним элементами упорядоченного массива базы. Это позволяет упростить и оптимизировать алгоримы поиска рабочих записей, сохраняя сами концевые записи недоступными. Причем обеспечивается возможность добавления в базу рабочих записей, также содержащих предельные значения ключевых полей. Все приведенные алгоритмы работы с базой предполагают обязательное наличие концевых записей. Решение, предусматривающее такие записи, может оказаться весьма полезным и при использовании классических баз данных.
#include <stdlib.h> #include <string.h>
Программа обращается к функциям стандартных библиотек С. Из <stdlib.h> используются функции выделения динамической памяти, а из <string.h> вызываются функции инициализации и копирования ее сегментов.
#define NOF_OBJECTS 800 // Максимальный размер базы #define INC_OBJECTS 10 // Инкремент размера базы по мере ее заполнения #define ERROR_NOTFOUND -12 // Запись не найдена #define ERROR_DUPLICATED -11 // Дублированный ключ #define ERROR_MALLOC -10 // Переполнение базы либо ошибка выделения памяти #define ERROR -1 #define OK 1 #define K1_LESS_K2 -1 // Результат сравнения ключей: K1 < K2 #define K1_EQUAL_K2 0 // Результат сравнения ключей: K1 = K2 #define K1_MORE_K2 1 // Результат сравнения ключей: K1 > K2 #define INT8_MIN -128 #define INT8_MAX 127 #define UNSIGNED16_MIN 0 #define UNSIGNED16_MAX 65535 typedef signed char int8; typedef unsigned char unsigned8; typedef signed short int16; typedef unsigned short unsigned16; typedef signed int int32; typedef unsigned int unsigned32;
Некоторые компиляторы интерпретируют типы, не содержащие ключевого слова signed как беззнаковые. Это вызывает смешанные чувства, но поскольку факт имеет место, целесообразно применять явное определение знаковости (signed или unsigned).
typedef struct {
unsigned16 key_1; // Ключевое поле большего приоритета
int8 key_2; // Ключевое поле меньшего приоритета
unsigned8 data_1;
unsigned16 data_2;
int32 data_3;
} object; // Запись базы данных
int32 objtot; // Текущий размер базы
int32 objfill; // Номер максимальной записи базы
object *objbase; // Указатель начала базы данных
int16 key_object(object *obj1, object *obj2) // ko_0
{
if (obj1->key_1 < obj2->key_1) return K1_LESS_K2; // ko_2
if (obj1->key_1 > obj2->key_1) return K1_MORE_K2; // ko_3
if (obj1->key_2 < obj2->key_2) return K1_LESS_K2; // ko_4
if (obj1->key_2 > obj2->key_2) return K1_MORE_K2; // ko_5
return K1_EQUAL_K2; // ko_6
}Функция key_object(obj1, obj2) определяет соотношение ключей двух записей базы. Сначала сравнивается первое поле ключей [ko_2, ko_3], имеющее более высокий приоритет. Если это поле у обоих ключей одинаково, осуществляется сравнение второго поля [ko_4, ko_5]. По результатам этих сравнений принимается решение о соотношении ключей (больше, меньше, равно) двух записей базы.
int32 search_object(object *obj) // so_0
{
int32 first, last, med;
int16 cmp;
first = 0;
last = objfill;
while (last - first > 1) { // so_7
med = (first + last) / 2;
cmp = key_object(obj, objbase+med);
if (cmp == K1_LESS_K2) last = med;
else if (cmp == K1_MORE_K2) first = med;
else return med; // so_12
}
return -1; // so_14
}Функция search_object(obj) осуществляет бинарный поиск записи базы по значению ключа, содержащемуся в объекте obj, указатель на который является входным параметром функции. При обнаружении в базе данных искомой записи возвращается неотрицательное число - положение (смещение) записи относительно начала базы [so_12]. Если же таковой не обнаружено, функция возвращает минус 1 [so_14].
Важным и полезным свойством используемого алгоритма является то, что искомая запись всегда расположена между левой и правой границами поиска, а сами эти границы всегда находятся в пределах заполненного сегмента базы данных. Таким образом, невозможно обращение к адресам, выходящим за пределы выделенного для базы сегмента памяти. Кроме того, максимальное число итераций алгоритма уменьшается на единицу, хотя условие завершения цикла поиска становится более сложным [so_7]. Алгоритм адаптирован для случая, когда в базе присутствуют концевые записи, благодаря чему не требуются дополнительные сравнения значений ключа первой и последней записей базы. Это позволяет также избежать проверки пустоты базы, когда значение номера максимальной записи (переменная objfill) отрицательно.
void insert_object(object *obj, int32 pos) // io_0
{
int32 cnt;
objfill++; // io_4
for (cnt = objfill; cnt > pos; cnt--) { // io_5
memcpy(objbase+cnt, objbase+cnt-1, sizeof(object)); // io_6
} // io_7
memcpy(objbase+pos, obj, sizeof(object)); // io_8
}Функция insert_object(obj, pos) производит вставку новой записи, положение которой (смещение относительно начала базы) задается параметром pos. Для этого осуществляется раздвижка базы: инкремент номера максимальной записи [io_4] и цикл копирования массива базы [io_5...io_7]. Затем на освободившуюся позицию заносится новая запись [io_8]. Именно необходимость проведения раздвижки при добавлении записи обуславливает пропорциональную зависимость O(N) относительного числа операций от размера базы.
int16 add_object(object *obj) // ao_0
{
void *newbase;
int32 first, last, med;
int16 cmp;
if (objfill+1 >= objtot) { // ao_6
newbase = NULL;
objtot += INC_OBJECTS; // ao_8
if (objtot <= NOF_OBJECTS) { // ao_9
newbase = realloc(objbase, objtot*sizeof(object)); // ao_10
}
if (newbase == NULL) {
objtot -= INC_OBJECTS;
return ERROR_MALLOC;
}
objbase = newbase;
}
first = 0; // ao_18
last = objfill;
while (last - first > 1) {
med = (first + last) / 2;
cmp = key_object(obj, objbase+med);
if (cmp == K1_LESS_K2) last = med;
else if (cmp == K1_MORE_K2) first = med;
else return ERROR_DUPLICATED; // ao_25
} // ao_26
insert_object(obj, last); // ao_27
return OK;
}Функция add_object(obj) осуществляет комплекс операций по добавлению записи в базу. В случае, если выделенный ранее массив памяти уже заполнен [ao_6], предпринимается запрос дополнительного объема памяти [ao_8...ao_10]. Параметр INC_OBJECTS, задающий инкремент размера базы по мере ее заполнения, выбирается таким, чтобы обращение к функции выделения памяти [ao_10] было не слишком частым (это весьма затратная операция), а с другой стороны, в базе не оставалось бы слишком много пустых записей (их число может достигать INC_OBJECTS-1). Ошибка добавления памяти может возникать как при безуспешном завершении запроса [ao_10], так и в случае превышения максимального размера базы (не выполнено условие [ao_9]).
Если все необходимые операции по выделению дополнительной памяти завершились успешно, производится бинарный поиск места [ao_18...ao_26], куда должна быть вставлена новая запись. При этом контролируется возможное дублирование ключа и при обнаружении такового возвращается код ошибки [ao_25]. В случае успешного нахождения положения новой записи производится ее вставка [ao_27]. Как и в функции поиска записи по ключу, алгоритм адаптирован для случая, когда в базе присутствуют концевые записи, причем их наличие является обязательным.
int16 delete_object(object *obj) // do_0
{
int32 pos, cnt;
pos = search_object(obj);
if (pos < 0) return ERROR_NOTFOUND;
for (cnt = pos; cnt < objfill; cnt++) { // do_6
memcpy(objbase+cnt, objbase+cnt+1, sizeof(object));
}
objfill--; // do_9
return OK;
}Функция delete_object(obj) удаляет из базы запись со значением ключа, содержащимся в объекте obj, указатель на который передается в качестве входного параметра. Если искомая запись обнаружена, производится сдвижка базы, удаляющая эту запись [цикл do_6], и номер максимальной записи уменьшается на единицу [do_9].
int32 set_object_prev(object *obj) // sp_0
{
int32 first, last, med;
int16 cmp;
first = 0;
last = objfill;
while (last - first > 1) {
med = (first + last) / 2;
cmp = key_object(obj, objbase+med);
if (cmp == K1_LESS_K2) last = med;
else if (cmp == K1_MORE_K2) first = med;
else return med;
}
if (first == 0) return -1; // sp_14
return first; // sp_15
}Функция set_object_prev(obj) возвращает положение записи, ключ которой менее либо равен ключу, содержащемуся в объекте obj. Если таких записей в базе нет, возвращается минус 1 [sp_14]. Функция дает возможность произвести выборку всех записей базы в определенном диапазоне значений высокоприоритетного поля ключа. Для этого величина поля высокого приоритета устанавливается на максимальное значение диапазона, а низкоприоритетных полей ключа – на максимально возможное их значение и вызывается функция set_object_prev(obj). Затем осуществляется последовательная выборка всех записей базы в сторону уменьшения адресов до тех пор, пока значение высокоприоритетного поля ключа остается в пределах заданного диапазона. Если база может содержать рабочую запись с минимально возможным значением высокоприоритетного поля ключа, необходимо дополнительно проверять нахождение текущей записи в пределах от 1 до objfill-1 включительно. Отметим, что оператор [sp_14], возвращающий минус 1, не является обязательным. При его исключении функция может вернуть положение левой концевой записи (ноль) [sp_15].
int32 set_object_next(object *obj) // sn_0
{
int32 first, last, med;
int16 cmp;
first = 0;
last = objfill;
while (last - first > 1) {
med = (first + last) / 2;
cmp = key_object(obj, objbase+med);
if (cmp == K1_LESS_K2) last = med;
else if (cmp == K1_MORE_K2) first = med;
else return med;
}
if (last == objfill) return -1;
return last;
}Функция set_object_next(obj) возвращает положение записи, ключ которой больше либо равен ключу, содержащемуся в объекте obj. Если таких записей в базе нет, возвращается минус 1 (см. замечание по поводу оператора [sp_14] функции set_object_prev(obj)). Функция дает возможность произвести выборку всех записей базы в определенном диапазоне значений высокоприоритетного поля ключа. Для этого величина поля высокого приоритета устанавливается на минимальное значение диапазона, а низкоприоритетных полей ключа – на минимально возможное их значение и вызывается функция set_object_next(obj). Затем осуществляется последовательная выборка всех записей базы в сторону увеличения адресов до тех пор, пока значение высокоприоритетного поля ключа остается в пределах заданного диапазона. Если база может содержать рабочую запись с максимально возможным значением высокоприоритетного поля ключа, необходимо дополнительно проверять нахождение текущей записи в пределах от 1 до objfill-1 включительно.
int16 init_database(void) // id_0
{
object obj;
objfill = -1; // id_4
objtot = 2 + INC_OBJECTS; // id_5
objbase = malloc(objtot*sizeof(object)); // id_6
if (objbase == NULL) return ERROR_MALLOC; // id_7
memset(&obj, 0, sizeof(obj)); // id_8
obj.key_1 = UNSIGNED16_MIN;
obj.key_2 = INT8_MIN;
insert_object(&obj, 0); // id_11
obj.key_1 = UNSIGNED16_MAX;
obj.key_2 = INT8_MAX;
insert_object(&obj, 1); // id_14
return OK;
}Функция инициализации базы данных init_database() устанавливает начальное значение переменных описания базы [id_4, id_5] и осуществляет первичное выделение памяти [id_6, id_7]. Затем в базу заносятся концевые записи [id_8...id_14]: запись с минимальным значением ключевых полей размещается по нулевому адресу [id_11], а с максимальным – по первому [id_14].
В нашей реализации базы данных используется дополнение массивов внешних ключей концевыми записями, которые содержат максимальные и минимальные значения всех полей, являясь первым и последним элементами упорядоченного массива ключа. Это позволяет упростить и оптимизировать алгоримы поиска по ключу, сохраняя сами концевые записи недоступными. Причем обеспечивается возможность добавления в базу рабочих записей, также содержащих предельные значения ключевых полей. Все приведенные алгоритмы работы с базой предполагают обязательное наличие концевых записей. Решение, предусматривающее такие записи, может оказаться весьма полезным и при использовании классических баз данных.
#include <stdlib.h> #include <string.h>
Программа обращается к функциям стандартных библиотек С. Из <stdlib.h> используются функции выделения динамической памяти, а из <string.h> вызываются функции инициализации и копирования ее сегментов.
#define NOF_OBJECTS 800 // Максимальный размер базы #define INC_OBJECTS 10 // Инкремент размера базы по мере ее заполнения #define ERROR_NOTFOUND -12 // Запись не найдена #define ERROR_DUPLICATED -11 // Дублированный ключ #define ERROR_MALLOC -10 // Переполнение базы либо ошибка выделения памяти #define ERROR -1 #define OK 1 #define K1_LESS_K2 -1 // Результат сравнения ключей: K1 < K2 #define K1_EQUAL_K2 0 // Результат сравнения ключей: K1 = K2 #define K1_MORE_K2 1 // Результат сравнения ключей: K1 > K2 #define INT8_MIN -128 #define INT8_MAX 127 #define UNSIGNED16_MIN 0 #define UNSIGNED16_MAX 65535 #define UNSIGNED32_MIN 0 #define UNSIGNED32_MAX 4294967295 typedef signed char int8; typedef unsigned char unsigned8; typedef signed short int16; typedef unsigned short unsigned16; typedef signed int int32; typedef unsigned int unsigned32;
Некоторые компиляторы интерпретируют типы, не содержащие ключевого слова signed как беззнаковые. Это вызывает смешанные чувства, но поскольку факт имеет место, целесообразно применять явное определение знаковости (signed или unsigned).
typedef struct {
unsigned16 data_k1_1; // Дублированное поле первого ключа
int8 data_k1_2; // Дублированное поле первого ключа
unsigned32 data_k2; // Дублированное поле второго ключа
unsigned8 data_1;
unsigned16 data_2;
int32 data_3;
} object; // Запись тела базы
typedef struct {
unsigned16 data_k1_1; // Ключевое поле большего приоритета первого ключа
int8 data_k1_2; // Ключевое поле меньшего приоритета первого ключа
int32 obp; // Смещение записи тела базы относительно ее начала
} key_1; // Запись первого ключа
typedef struct {
unsigned32 data_k2; // Ключевое поле второго ключа
int32 obp; // Смещение записи тела базы относительно ее начала
} key_2; // Запись второго ключа
int32 objtot; // Текущий размер тела базы
int32 objfill; // Номер максимальной записи тела базы
int32 keytot; // Текущий размер ключевых баз
int32 keyfill; // Номер максимальной записи ключевых баз
object *objbase; // Указатель начала тела базы данных
key_1 *k1_base; // Указатель начала базы первого ключа
key_2 *k2_base; // Указатель начала базы второго ключа
int16 key_1_compare(key_1 *k1, key_1 *k2) // k1c_0
{
if (k1->data_k1_1 < k2->data_k1_1) return K1_LESS_K2; // k1c_2
if (k1->data_k1_1 > k2->data_k1_1) return K1_MORE_K2; // k1c_3
if (k1->data_k1_2 < k2->data_k1_2) return K1_LESS_K2; // k1c_4
if (k1->data_k1_2 > k2->data_k1_2) return K1_MORE_K2; // k1c_5
return K1_EQUAL_K2;
}Функция key_1_compare(k1, k2) определяет соотношение первых ключей базы. Сначала сравнивается первое поле ключей [k1c_2, k1c_3], имеющее более высокий приоритет. Если это поле у обоих ключей одинаково, осуществляется сравнение второго поля [k1c_4, k1c_5]. По результатам этих сравнений принимается решение о соотношении ключей (больше, меньше, равно).
int32 search_object_k1(key_1 *key) // so1_0
{
int32 first, last, med;
int16 cmp;
first = 0;
last = keyfill;
while (last - first > 1) { // so1_7
med = (first + last) / 2;
cmp = key_1_compare(key, k1_base+med);
if (cmp == K1_LESS_K2) last = med;
else if (cmp == K1_MORE_K2) first = med;
else return (k1_base+med)->obp; // so1_12
}
return -1; // so1_14
}Функция search_object_k1(key) осуществляет бинарный поиск записи по значению первого ключа key, указатель на который является входным параметром функции. При обнаружении в базе ключей искомой записи возвращается неотрицательное число - положение (смещение) соответствующей записи тела базы относительно ее начала [so1_12]. Если подходящей ключевой записи не обнаружено, функция возвращает минус 1 [so1_14].
int32 search_object_k2(key_2 *key) // so2_0
{
int32 first, last, med;
first = 0;
last = keyfill;
while (last - first > 1) { // so2_6
med = (first + last) / 2;
if (key->data_k2 < (k2_base+med)->data_k2) last = med; // so2_8
else if (key->data_k2 > (k2_base+med)->data_k2) first = med; // so2_9
else return (k2_base+med)->obp; // so2_10
}
return -1; // so2_12
}Функция search_object_k2(key) осуществляет бинарный поиск записи по значению второго ключа key, указатель на который является входным параметром функции. При обнаружении в базе ключей искомой записи возвращается неотрицательное число - положение (смещение) соответствующей записи тела базы относительно ее начала [so2_10]. Если подходящей ключевой записи не обнаружено, функция возвращает минус 1 [so2_12]. Поскольку второй ключ не является составным, используются операции непосредственного сравнения значения ключевого поля [so2_8, so2_9].
Полезным свойством используемых алгоритмов является то, что искомая запись всегда расположена между левой и правой границами поиска, а сами эти границы всегда находятся в пределах заполненного сегмента базы ключей. Таким образом, невозможно обращение к адресам, выходящим за пределы выделенного для базы сегмента памяти. Кроме того, максимальное число итераций алгоритма уменьшается на единицу, хотя условие завершения цикла поиска становится более сложным [so1_7], [so2_6]. Алгоритм адаптирован для случая, когда в базе присутствуют концевые записи, благодаря чему не требуются дополнительные сравнения значений первой и последней записей ключа. Это позволяет также избежать проверки пустоты базы, когда значение номера максимальной записи (переменная keyfill) отрицательно.
int16 add_object(object *obj) // ao_0
{
void *newbase1, *newbase2;
key_1 k1;
key_2 k2;
int32 first, med, k1last, k2last, cnt;
int16 cmp;
if (objfill+1 >= objtot) { // ao_8
newbase1 = NULL;
objtot += INC_OBJECTS;{ // ao_10
if (objtot <= NOF_OBJECTS) { // ao_11
newbase1 = realloc(objbase, objtot*sizeof(object));{ // ao_12
}
if (newbase1 == NULL) {
objtot -= INC_OBJECTS;
return ERROR_MALLOC;
}
objbase = newbase1;
}
if (keyfill+1 >= keytot) { // ao_20
newbase1 = NULL;
newbase2 = NULL;
keytot += INC_OBJECTS; // ao_23
if (keytot <= NOF_OBJECTS) { // ao_24
newbase1 = realloc(k1_base, keytot*sizeof(key_1)); // ao_25
newbase2 = realloc(k2_base, keytot*sizeof(key_2)); // ao_26
}
if (newbase1 == NULL || newbase2 == NULL) {
keytot -= INC_OBJECTS;
return ERROR_MALLOC;
}
k1_base = newbase1;
k2_base = newbase2;
}
k1.data_k1_1 = obj->data_k1_1; // ao_35
k1.data_k1_2 = obj->data_k1_2;
first = 0;
k1last = keyfill;
while (k1last - first > 1) {
med = (first + k1last) / 2;
cmp = key_1_compare(&k1, k1_base+med);
if (cmp == K1_LESS_K2) k1last = med;
else if (cmp == K1_MORE_K2) first = med;
else return ERROR_DUPLICATED; // ao_44
} // ao_45
k2.data_k2 = obj->data_k2; // ao_46
first = 0;
k2last = keyfill;
while (k2last - first > 1) {
med = (first + k2last) / 2;
if (k2.data_k2 < (k2_base+med)->data_k2) k2last = med;
else if (k2.data_k2 > (k2_base+med)->data_k2) first = med;
else return ERROR_DUPLICATED; // ao_53
} // ao_54
objfill++;
memcpy(objbase+objfill, obj, sizeof(object)); // ao_56
k1.obp = objfill; // ao_57
k2.obp = objfill; // ao_58
keyfill++;
for (cnt = keyfill; cnt > k1last; cnt--) { // ao_60
memcpy(k1_base+cnt, k1_base+cnt-1, sizeof(key_1));
}
memcpy(k1_base+k1last, &k1, sizeof(key_1)); // ao_63
for (cnt = keyfill; cnt > k2last; cnt--) { // ao_64
memcpy(k2_base+cnt, k2_base+cnt-1, sizeof(key_2));
}
memcpy(k2_base+k2last, &k2, sizeof(key_2)); // ao_67
return OK;
}Функция add_object(obj) осуществляет комплекс операций по добавлению записи в базу. В случае, если выделенные ранее массивы памяти уже заполнены ([ao_8] для тела базы, [ao_20] для массивов ключей), предпринимается запрос дополнительного объема памяти [ao_10...ao_12] для тела базы и [ao_23...ao_26] для ключей. Параметр INC_OBJECTS, задающий инкремент размера всех массивов базы по мере ее заполнения, выбирается таким, чтобы обращения к функции выделения памяти [ao_12, ao_25, ao_26] были не слишком частыми (это весьма затратная операция), а с другой стороны, в базе не оставалось бы слишком много пустых записей (их число может достигать INC_OBJECTS-1). Ошибка добавления памяти может возникать как при безуспешном завершении запросов, так и в случае превышения максимального размера базы (не выполнены условия [ao_11, ao_24]).
Если все необходимые операции по выделению дополнительной памяти завершились успешно, производится бинарный поиск места вставки ключевых записей: [ao_35...ao_45] для первого ключа и [ao_46...ao_54] для второго. При этом контролируется возможное дублирование по каждому ключу и при обнаружении такового возвращается код ошибки [ao_44] – первый ключ, [ao_53] второй. В случае успешного завершения всех проверок производится вставка новой записи в конец тела базы [ao_56] и установ соответствующих указателей в ключах [ao_57, ao_58]. Затем осуществляется раздвижка баз ключей [ao_60, ao_64] и они заносятся в определенные для них позиции [ao_63, ao_67]. Как и в функции поиска записи по ключу, алгоритм адаптирован для случая, когда в базе присутствуют концевые записи, причем их наличие является обязательным.
int16 delete_object(object *obj) // do_0
{
int32 pos1, pos2, posobj, cnt;
int32 first, last, med;
int16 cmp;
key_1 k1;
pos1 = -1;
k1.data_k1_1 = obj->data_k1_1;
k1.data_k1_2 = obj->data_k1_2;
first = 0;
last = keyfill;
while (last - first > 1) { // do_12
med = (first + last) / 2;
cmp = key_1_compare(&k1, k1_base+med);
if (cmp == K1_LESS_K2) last = med;
else if (cmp == K1_MORE_K2) first = med;
else {
pos1 = med;
break;
}
}
if (pos1 < 0) return ERROR_NOTFOUND;
pos2 = -1;
first = 0;
last = keyfill;
while (last - first > 1) { // do_26
med = (first + last) / 2;
if (obj->data_k2 < (k2_base+med)->data_k2) last = med;
else if (obj->data_k2 > (k2_base+med)->data_k2) first = med;
else {
pos2 = med;
break;
}
}
if (pos2 < 0) return ERROR_NOTFOUND;
posobj = (k1_base+pos1)->obp; // do_36
for (cnt = pos1; cnt < keyfill; cnt++) { // do_37
memcpy(k1_base+cnt, k1_base+cnt+1, sizeof(key_1));
}
for (cnt = pos2; cnt < keyfill; cnt++) { // do_40
memcpy(k2_base+cnt, k2_base+cnt+1, sizeof(key_2));
}
keyfill--; // do_43
for (cnt = posobj; cnt < objfill; cnt++) { // do_44
memcpy(objbase+cnt, objbase+cnt+1, sizeof(object));
}
objfill--;
for (cnt = 1; cnt < keyfill; cnt++) { // do_48
if ((k1_base+cnt)->obp > posobj) (k1_base+cnt)->obp--;
if ((k2_base+cnt)->obp > posobj) (k2_base+cnt)->obp--;
}
return OK;
}Функция delete_object(obj) удаляет из базы запись со значениями ключей, содержащимися в объекте obj, указатель на который передается в качестве входного параметра. Искомая запись ищется независимо по каждому ключу [do_12, do_26]. Если она обнаружена в обоих массивах ключей, производится их сдвижка: цикл [do_37] удаляет первый ключ, а [do_40] второй. Соответственно номер максимальной записи ключевых баз уменьшается на единицу [do_43].
На том можно было бы и завершить удаление – соответствующая запись теперь недоступна при поиске по любому ключу. Но в таком случае в теле базы будут накапливаться не рабочие записи, поэтому имеет смысл также их удалять. Это довольно трудоемкая операция. Сначала производится сдвижка тела базы [do_44] (расположение удаляемой записи было зафиксировано в [do_36]). Затем для поддержания состоятельности ссылок ключей необходимо осуществить соответствующую корректировку (декремент) указателей, ссылающихся на записи тела базы, которые размещались вслед за удаленной [do_48]. Таким образом, тяжесть полного удаления записи весьма высока. Однако в приложениях эта операция обычно наиболее редка и с повышенным объемом вычислительной работы вполне можно смириться.
int32 set_k1_prev(key_1 *key) // sp_0
{
int32 first, last, med;
int16 cmp;
first = 0;
last = keyfill;
while (last - first > 1) {
med = (first + last) / 2;
cmp = key_1_compare(key, k1_base+med);
if (cmp == K1_LESS_K2) last = med;
else if (cmp == K1_MORE_K2) first = med;
else return med;
}
return first;
}Функция set_k1_prev(key) возвращает положение записи, первый ключ которой менее либо равен ключу key. Функция дает возможность произвести выборку всех записей базы в определенном диапазоне значений высокоприоритетного поля ключа. Для этого величина поля высокого приоритета устанавливается на максимальное значение диапазона, а низкоприоритетных полей ключа – на максимально возможное их значение и вызывается функция set_k1_prev(key). Затем осуществляется последовательная выборка всех записей базы в сторону уменьшения адресов до тех пор, пока значение высокоприоритетного поля ключа остается в пределах заданного диапазона. Если база может содержать рабочую запись с минимально возможным значением высокоприоритетного поля ключа, необходимо дополнительно проверять нахождение текущей записи ключа в пределах от 1 до keyfill-1 включительно.
int32 set_k1_next(key_1 *key) // sn_0
{
int32 first, last, med;
int16 cmp;
first = 0;
last = keyfill;
while (last - first > 1) {
med = (first + last) / 2;
cmp = key_1_compare(key, k1_base+med);
if (cmp == K1_LESS_K2) last = med;
else if (cmp == K1_MORE_K2) first = med;
else return med;
}
return last;
}Функция set_k1_next(key) возвращает положение записи, первый ключ которой больше либо равен ключу key. Функция дает возможность произвести выборку всех записей базы в определенном диапазоне значений высокоприоритетного поля ключа. Для этого величина поля высокого приоритета устанавливается на минимальное значение диапазона, а низкоприоритетных полей ключа – на минимально возможное их значение и вызывается функция set_k1_next(key). Затем осуществляется последовательная выборка всех записей базы в сторону увеличения адресов до тех пор, пока значение высокоприоритетного поля ключа остается в пределах заданного диапазона. Если база может содержать рабочую запись с максимально возможным значением высокоприоритетного поля ключа, необходимо дополнительно проверять нахождение текущей записи ключа в пределах от 1 до keyfill-1 включительно.
int16 init_database(void) // id_0
{
key_1 k1;
key_2 k2;
objfill = -1; // id_5
keyfill = -1; // id_6
objtot = INC_OBJECTS; // id_7
objbase = malloc(objtot*sizeof(object)); // id_8
if (objbase == NULL) return ERROR_MALLOC; // id_9
keytot = 2+INC_OBJECTS; // id_10
k1_base = malloc(keytot*sizeof(key_1)); // id_11
if (k1_base == NULL) return ERROR_MALLOC;
k2_base = malloc(keytot*sizeof(key_2));
if (k2_base == NULL) return ERROR_MALLOC; // id_14
k1.obp = 0; // id_15
k1.data_k1_1 = UNSIGNED16_MIN;
k1.data_k1_2 = INT8_MIN;
memcpy(k1_base, &k1, sizeof(key_1)); // id_18
k1.data_k1_1 = UNSIGNED16_MAX;
k1.data_k1_2 = INT8_MAX;
memcpy(k1_base+1, &k1, sizeof(key_1)); // id_21
k2.obp = 0; // id_22
k2.data_k2 = UNSIGNED32_MIN;
memcpy(k2_base, &k2, sizeof(key_2)); // id_24
k2.data_k2 = UNSIGNED32_MAX;
memcpy(k2_base+1, &k2, sizeof(key_2)); // id_26
keyfill = 1; // id_27
return OK;
}Функция инициализации базы данных init_database() устанавливает начальное значение переменных описания базы [id_5...id_7, id_10], затем осуществляет первичное выделение памяти для тела базы [id_8, id_9] и двух ключей [id_11...id_14]. Затем в базу заносятся концевые записи по первому [id_15...id_21] и второму ключам [id_22...id_26]. Записи с минимальным значением ключевых полей размещаются по нулевому адресу [id_18, id_24], а с максимальным – по первому [id_21, id_26]. Номер максимальной записи ключевых баз соответственно устанавливается в единицу [id_27].